アークナイツのストーリー文をVoiceVoxで音声化し、字幕付き動画として出力するまでをPythonで半自動化しました。本記事では、一括音声化の手法と作成したソースコードをまとめます。
完成品の例:
VOICEVOX:冥鳴ひまり
https://voicevox.hiroshiba.jp
きっかけ
3年と少し前からアークナイツというゲームを続けています。
いわゆるソシャゲと言われるものですが、世界観の作り込みやストーリーの雰囲気が気に入っており、私が唯一プレイしているソシャゲです。何より運営のゲームの世界を楽しくしようという姿勢が気に入っており、ゲーム中で使用されないイメージソングを100曲以上作り続けていたり、鈍器の如き設定資料集を何冊も発刊していたりします。
そしてその心意気の甲斐あってか災いしてか、ストーリーの文章量がとにかく膨大なのです。
最近は一つのストーリーで20万文字をこえることもしばしばあり、一般的な文庫本が10万文字程度であることを考えるとその重さが伝わるでしょうか。しかもストーリーはボイスはなく文章形式であり、最近の忙しさもあってほとんど読めていないのが現状でした。
そこで、炊事家事・作業中にストーリーをながら摂取できる環境を整えるべく、ストーリーの音声化に着手しました。
目次
注意点
今回自動で生成した音声・動画は、個人でのみ利用する方針です。
アークナイツのストーリーをコピーに近い形でネット上で公開する行為は、著作権の侵害にあたる可能性があります。利用時はくれぐれも個人利用にとどめるようにしてください。
環境
OS:MacOS(arm64)
CPU:Apple M3
メモリ:16GB
環境構築
コードの実行環境は任意ですが、VScode上でターミナルとJupyterNotebookを操作する形が簡単でおすすめです。手順は以下の記事を参考にしてください。
❶ Pythonをインストール

❷ VScodeをインストール

❸ JupiterNotebookの環境構築
(記事のデバッグ以降の内容は今回は無視でOK)

また、今後の手順でライブラリのインストールが必要になった際は、記事③で開いたVScodeのターミナルで以下のコマンドを打てばインストールができます。
pip3 install ライブラリ名その他、構築上の疑問点はとりあえずChatGPTに投げてみると大体解決するのでおすすめです。解決しないご質問があれば、気軽にX(Twitter)までお声がけください。
1. VoiceVoxEngineの導入
今回は、音声認識ソフトとしてVoiceVoxを利用します。こちらはずんだもんや四国めたんで有名な音声合成ソフトで、無料にも関わらず十分な性能で利用できるツールです。
無料で高性能なのはもちろん、今回はPythonから呼び出して自動で音声合成を行わせる上で適していたためこちらを採用しました。VoiceVoxは通常のアプリに加えて、VoiceVoxEngineとして合成エンジン単体で利用できるファイルをGitHubで公開しています。
こちらを活用して、音声合成を行うためのAPIを備えたHTTPサーバをローカルに構築します。
1.1.ダウンロード
公式サイトから自身のOS に合うVoiceVox Engineファイルをダウンロードします。
私の環境はM3 MacOSなので、macOS(CPU/arm64版)をダウンロードしました。7-zipで圧縮されていたので、圧縮ファイルがあるフォルダーでターミナル(コマンドプロンプトなど)を開き、以下のコマンドで解凍します。
7z x ファイル名7-zipがインストールされておらず上記のコードが実行できない場合は、先にインストールが必要です。
macの場合は以下のコマンドでインストールできます。
brew install p7zipWindowsの場合は、以下からダウンロード&インストールを行ってください。

解凍すると、VoiceVox Engineを利用するためのバイナリ・ライブラリ・モデルファイルが一式揃ったアプリケーションフォルダーが得られます。
1.2.HTTPサーバの起動
ターミナルからVoiceVoxEngineアプリケーションを起動します。アプリケーションを起動することで、音声合成を行うための呼び出し口(HTTPサーバ+API)を用意することができます。
先ほど解凍したアプリケーションフォルダに移動して、以下の起動コマンドを打つことで起動できます。
cd フォルダ名./runHTTPサーバを停止したいときは、ターミナルでCtrl+Cを押してください。
1.3.Pythonから音声合成してみる
Pythonコードで、実際に音声を合成してみます。
以下のコードで定義した関数を実行することで、音声を合成してwavファイル化できます。textの部分を変えることで色々な言葉を音声化できるので、動作確認も兼ねて試してみてください。
# VOICEVOXを用いたセリフ出力用関数
import os
import requests
ENGINE_URL = "http://localhost:50021" # VOICEVOXエンジンのURL
SPEAKER_ID = 14 # キャラクター選択(VOICEVOX:冥鳴ひまり https://voicevox.hiroshiba.jp)
def make_voicefile(filename, text):
try:
# 1. 音声合成用のクエリを作成
query_response = requests.post(
f"{ENGINE_URL}/audio_query",
params={"text": text, "speaker": SPEAKER_ID}
)
query_response.raise_for_status()
query = query_response.json()
# 話し方調整
query["speedScale"] = 1.0 # 話す速度
query["pitchScale"] = 0.0 # 声の高さ
query["volumeScale"] = 1.0 # 声の大きさ
query["intonationScale"] = 1.0 # イントネーションの豊かさ
query["pauseLength"] = None # 間の広さ
# 2. 音声データを生成
synthesis_response = requests.post(
f"{ENGINE_URL}/synthesis",
params={"speaker": SPEAKER_ID},
json=query
)
synthesis_response.raise_for_status()
audio_data = synthesis_response.content
# 3. WAVファイルとして保存
os.makedirs("temp", exist_ok=True)
with open(f"temp/{filename}.wav", "wb") as f:
f.write(audio_data)
# print(f"生成完了: temp/{filename}.wav")
return filename
except Exception as e:
print(f"[ERROR] {filename}: {e}")
return Nonemake_voicefile("filename", "こんにちは、これはテストです。")SPEAKER_ID を調整することで、読み上げを行うキャラクターを変更することができます。今回はゆったりと落ち着いて読み上げてくれる「冥鳴ひまり」さんを採用しました。
詳細については、以下の記事も参考にしてください。今回はアークナイツのストーリーを読み上げさせるために最適化していますが、あちらでは汎用的な読み上げ音声作成ツールとしてまとめています。

2. ストーリーを音声化
VoiceVoxEngineが用意できたところで、早速アークナイツのストーリー文章を音声化する作業に入っていきます。
2.1.アークナイツのストーリーデータを取得
まずは、ストーリーの文章データを取得します。
アークナイツのストーリーに関しては、ASTRというサイトから取得します。こちらには有志の方々によってデータがまとめられており、ストーリーデータはもちろん、多言語対応や画像データ・キャラクター情報まで整備されており非常に有益なサイトです。

今回はサイドストーリー「銀心湖鉄道」の音声化に取り組んでみます。
メニューの「公共事業実録」からサイドストーリーを選択するとサブタイトルが一覧で表示され、Web上でストーリーを楽しむことができます。今回はページ上部の「Excelに出力する」から、文章データを一括でダウンロードします。
Excelの中身は話者・セリフの構造化データになっており、さらにシーンごとの背景画像リンクも完備された優れものです。
2.2.サブタイトルの登録
ここから、Pythonへのデータ登録作業に移っていきます。
まずは各話のサブタイトルを取得します。サブタイトルはExcelデータには含まれていないため、コピー&ペーストで登録します。
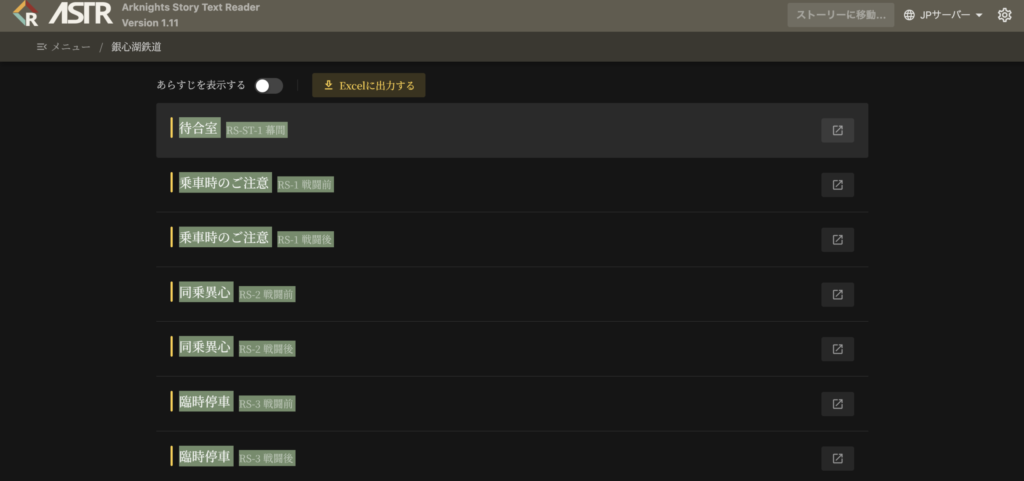
上記のようにサブタイトル全体を選択してコピーし、以下のPythonコードの3~40行目の部分にペーストしてください。このコードを実行することで登録が完了します。
# サブタイトル登録
input = """
待合室
RS-ST-1 幕間
乗車時のご注意
RS-1 戦闘前
乗車時のご注意
RS-1 戦闘後
同乗異心
RS-2 戦闘前
同乗異心
RS-2 戦闘後
臨時停車
RS-3 戦闘前
臨時停車
RS-3 戦闘後
軌道修正
RS-4 戦闘前
軌道修正
RS-4 戦闘後
登山鉄道
RS-ST-2 幕間
不正乗車?
RS-5 戦闘前
不正乗車?
RS-5 戦闘後
不正乗車の代償
RS-6 戦闘前
不正乗車の代償
RS-6 戦闘後
壊れたブレーキ
RS-7 戦闘前
壊れたブレーキ
RS-7 戦闘後
トップスピード
RS-8 戦闘前
トップスピード
RS-8 戦闘後
終点
RS-ST-3 幕間
""".split("\n")
subtitles = [input[i] + " " + input[i+1] for i in range(1, len(input)-1, 2)]2.3.ストーリーデータを読み込み
続いて、Excelから文章データを読み取っていきます。
まずは以下のコードで、Excelファイルを読み込みます。先ほどダウンロードしたExcelファイルを現在開いているJupyterNotebook(.ipynbファイル)と同じフォルダに置いて以下のコードを実行してください。
# エクセルの読み取り
import openpyxl
# ダウンロードしたエクセルをロードする
wb = openpyxl.load_workbook("act30side_銀心湖鉄道.xlsx")
sheet_names = wb.sheetnamesコード中の「act30side_銀心湖鉄道.xlsx」の部分は、読み込みたいサイドストーリーに応じてその時々のExcelファイル名に書き換えてください。
2.4.ストーリーデータの整形
読み込んだExcelデータから、音声や字幕が出力しやすいようにデータを整形していきます。
以下のコードを実行することで、1段階目の整形が完了します。
# ストーリーデータの読み取り
import re
# ストーリープロットを保存する配列
storyplots = []
# タブを順番に読み取ってプロットデータに保存する
for i in range(len(sheet_names)):
subtitle = subtitles[i]
ws = wb[sheet_names[i]]
# シーン管理用のtempデータ→storyplotsの要素として追加していく
seanMng = {
"subtitle" : subtitle,
"background" : "",
"characters" : [], # シーン中で登場するキャラクター一覧
"plots": [], # 字幕出力用テキストのリスト
"voiceScript": [] # 音声出力用テキストのリスト
}
# ドクターの選択コマンドに関する処理を管理する
preSpeaker = ""
branchMode = {
"faze": 0,
"endFrag": [
"--Decision--"
"Option",
">Options",
">Options",
"End of Options"
]
}
# 一行ずつ読み取り
for r in range(1, ws.max_row):
text = ws.cell(row=r, column=3).value
speaker = ws.cell(row=r, column=2).value
if speaker == None :
speaker = ""
elif speaker == "----":
continue
elif speaker in ["--background--", "--image--"]:
# 背景変更タイミングをシーン切り替えとして記録
if len(seanMng["characters"]) > 0:
storyplots.append(seanMng)
seanMng = {
"subtitle" : subtitle,
"background" : text,
"characters" : [],
"plots": [],
"voiceScript": []
}
preSpeaker = ""
continue
if text == None:
continue
# 選択コマンドの管理
if branchMode["faze"] == 0:
if speaker == "--Decision--":
branchMode["faze"] = 1
continue
elif speaker == "--Branch--":
branchMode["faze"] = 3
continue
elif branchMode["faze"] == 1:
if speaker.split("_")[0] != "Option":
continue
speaker = "ドクター"
branchMode["faze"] = 2
elif branchMode["faze"] == 2:
if text.split("_")[0] == ">Options":
branchMode["faze"] = 0
continue
elif branchMode["faze"] == 3:
if text == "End of Options":
branchMode["faze"] = 0
continue
# 不要なタグだった場合、スキップする
if speaker in ["--imagetween--"]:
continue
if speaker[:2] == "--":
print("スキップしました。未処理のタグがあります:", speaker)
continue
# タグの削除
text = re.sub("<[^>]+>", '', text)
text = re.sub("\\\\n", '', text)
# セリフの記録
replaceSpaceSymbol = lambda text :re.sub("[……,|――]", "\n", text) # voiceScriptの間を取るタイミングは「\n」記号で統一
if speaker == "":
seanMng["plots"].append({"speaker":None, "text":text.replace("\n", " ")})
elif speaker != preSpeaker:
seanMng["plots"].append({"speaker":speaker, "text":text.replace("\n", " ")})
else:
seanMng["plots"].append({"speaker":"", "text":text.replace("\n", " ")})
if not speaker in seanMng["characters"]:
seanMng["characters"].append(speaker)
seanMng["voiceScript"].append("\n" + speaker + "\n" + replaceSpaceSymbol(text))
else:
if speaker != preSpeaker:
seanMng["voiceScript"].append("\n" + replaceSpaceSymbol(text))
else:
seanMng["voiceScript"].append(replaceSpaceSymbol(text))
preSpeaker = speaker
if len(seanMng["characters"]) > 0:
storyplots.append(seanMng)コードの内容としては、読み込んだテキストを字幕用のテキストと音声用のテキストに分けてそれぞれ整形しています。
背景画像の変更をシーン変更とみなして、シーンごとに区切ったリストとしてstoryPlotsに保存しました。また読み上げに関しては、今回は各シーンで話者が初めて喋った時のみ話者名を読み上げる形式にしています。
さらに以下のコードで2段階目の整形を行います。
# データ整形
storyplotsResult = []
CharPerLine = 37 # 字幕の一行あたりの最大文字数
LinePerPage = 12 # 1画面に収める最大行数
# 字幕を表示行ごとに分割したリストにする & 音声スクリプトをwav出力用リストに細分割する
for sp in storyplots:
rowOfOutput = 0
checkPoint = 0
for i, item in enumerate(sp["plots"]):
# 行をざっくり指定文字数で区切る
speakerLen = 0 if item["speaker"] == None else len(item["speaker"])
lineNum = 1 + (speakerLen + len(item["text"]) -1) / (CharPerLine-1)
rowOfOutput += lineNum
line1end = CharPerLine - speakerLen -1
item["text"] = [item["text"][:line1end]] + [item["text"][j: j+(CharPerLine-1)] for j in range(line1end, len(item["text"]), CharPerLine-1)]
if rowOfOutput >= LinePerPage:
rowOfOutput = 0
storyplotsResult.append({
"subtitle" : sp["subtitle"],
"background" : sp["background"],
"characters" : sp["characters"],
"plots": sp["plots"][checkPoint:i],
"voiceScript": [x for row in sp["voiceScript"][checkPoint:i] for x in row.split("\n")] # \n*指定時間だけ間を取るために分割
})
checkPoint = i
rowOfOutput = 0
if rowOfOutput > 0:
storyplotsResult.append({
"subtitle" : sp["subtitle"],
"background" : sp["background"],
"characters" : sp["characters"],
"plots": sp["plots"][checkPoint:],
"voiceScript": [x for row in sp["voiceScript"][checkPoint:] for x in row.split("\n")]
})こちらでは、字幕が画面内に収まるようにするための整形を実施しています。行列数を指定して改行を挟むとともに、シーンを字幕1ページごとにさらに細分化してstoryplotsResultに保存します。
2.5.ストーリーデータを音声合成
ここからは、実際に音声合成を行なっていきます。
2.4までの手順に加えて、事前準備として以下の3点が必要です。
❶ 1.2で行ったHTTPサーバの起動
❷ 1.3で作成した関数コードの実行
❸ 以下の関数コードの実行(作成したセリフのwavファイルを結合する関数)
# 出力したセリフを結合する関数の定義
from pydub import AudioSegment
from concurrent.futures import ThreadPoolExecutor, as_completed
voiceMargin = 450 # 各インデックスの後ろに指定msの間を追加する
def connect_wav(start_index, end_index):
combined_audio = AudioSegment.empty()
previous_index = None
for idx in range(start_index, end_index):
filepath = f"temp/{idx}.wav"
if os.path.exists(filepath):
audio = AudioSegment.from_wav(filepath)
# 間にあった空のセリフデータの分だけ間の時間を延長する
if previous_index is not None:
missing = idx - previous_index - 1
gap_duration_ms = (missing + 1) * voiceMargin
combined_audio += AudioSegment.silent(duration=gap_duration_ms)
combined_audio += audio
os.remove(filepath) # 結合済みのtempファイルを削除する
# print(f"結合&削除: {filepath}")
previous_index = idx
# 合成した音声ファイルを出力
if len(combined_audio) > 0:
os.makedirs("output", exist_ok=True)
output_path = f'output/r_{end_index}.wav'
combined_audio.export(output_path, format="wav")
print(f"{output_path} を出力")
else:
print("有効な音声ファイルがありませんでした。")以上の事前準備をした上で、以下のコードでストーリー全体に音声合成を適用できます。
# 音声出力メイン処理
wav_index = 0
pre_export_index = 0
max_workers = 5 # 並列実行数
for i, sp in enumerate(storyplotsResult):
tasks = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
for text in sp["voiceScript"]:
# 空でないセリフデータに対してのみ出力を実行する(空のセリフについては間を延長)
if text.strip():
future = executor.submit(make_voicefile, str(wav_index), text)
tasks.append(future)
wav_index += 1
# 全タスクが終了するのを待機
for future in as_completed(tasks):
future.result()
connect_wav(pre_export_index, wav_index)
pre_export_index = wav_index
storyplotsResult[i]["wavfile"] = f"r_{wav_index}.wav"自分の環境では実行に2時間(14万文字あたり)かかりました。PCのスペックが足りていないとさらに時間を要するので、PCを勝手にスリープしない設定にして気長に待ちましょう。
コードの内容としては、まず各セリフ単位で音声合成し、その後セリフごとに間を空けながらシーンごとの音声ファイルとして結合しています。
各シーンを一括でVoiceVoxエンジンに投入してしまうと句読点の間が短く不自然になってしまうため、一度セリフとして出力した後に結合する方式を取っています。間を広く空けたいような場面については、storyPlotsResultのvoiceScript要素に空白のリストを追加することで、空白の数だけ間の時間を延長する仕様です。
2.6.音声ファイルとして各話を出力(おまけ)
メインの流れとしては、この節は飛ばして動画出力の章に進みます。
しかし、今回出力する動画ファイルは22.4GBにもなり、気軽に楽しむには少々扱いづらいサイズです。そのため、容量が小さい音声ファイルとして楽しみたい人向けに、wavファイルとして各話に分けて出力するコードも紹介しておきます。
# 音声として出力したい場合
silence = AudioSegment.silent(duration=int(voiceMargin)) # 無音データ(pydubでミリ秒指定)
combined = AudioSegment.empty()
sidx = 0
for item in storyplotsResult:
wavfile = item.get("wavfile")
if wavfile is None:
continue
if item["subtitle"] != subtitles[sidx]:
output_path = os.path.join("output", f"{sidx}_{subtitles[sidx]}.wav")
combined.export(output_path, format="wav")
print(f"結合済み音声ファイルを出力しました: {output_path}")
combined = AudioSegment.empty()
sidx += 1
filename = os.path.join("output", f"{wavfile}")
if os.path.exists(filename):
audio = AudioSegment.from_wav(filename)
if len(combined) > 0:
combined += silence # 前に音声がある場合のみ無音を挿入
combined += audio上記のコードで出力したwavファイルであれば、サイズも合計で1.3GBほどに抑えられます。
3. 動画データとして出力
作成したwavファイルを元に、字幕と背景画像をつけた動画データとして出力していきます。
今回は動画編集ソフトとしてDavinciResolve(無料版)を利用しました。Pythonでインポート用のファイルを作成して、動画編集ソフトのタイムラインにインポートすることで動画化しています。
タイムラインデータをXMLファイル(Final Cut Pro 7形式)として、字幕データを.srtファイルとして出力しているので、DavinciResolve以外の動画編集ソフトにも流用できると思います。
3.1.背景画像をダウンロード
背景用の画像データをインターネットから一括ダウンロードします。
以下のコードで一括ダウンロードができます。
# 背景画像のダウンロード
import os
import requests
from urllib.parse import urlparse
temp_dir = "img"
os.makedirs(temp_dir, exist_ok=True)
# Aceship氏のリポジトリに未保存の画像については、Fexli氏のリポジトリから取得させて頂く
fallback_base_url = "https://raw.githubusercontent.com/fexli/ArknightsResource/main/avgs/"
readList = []
for idx, item in enumerate(storyplotsResult):
bg_url = item["background"]
# URL末尾のファイル名を取得
if bg_url == "":
bg_url = "https://raw.githubusercontent.com/Aceship/Arknight-Images/main/avg/backgrounds/bg_black.png"
filename = os.path.basename(urlparse(bg_url).path)
save_path = os.path.join(temp_dir, filename)
storyplotsResult[idx]["imgFile"] = filename
dir = "bg/" if bg_url.split("/")[-2] == "backgrounds" else "" # Aceship氏のディレクトリ調整
# すでに存在する場合はスキップ
if filename in readList:
# print(f"スキップ: {save_path}(既に存在)")
continue
# 1回目:オリジナルURL(Aceship氏のリポジトリ)でダウンロード
response = requests.get(bg_url)
if response.status_code == 200:
with open(save_path, "wb") as f:
f.write(response.content)
print(f"保存しました: {save_path}(from:Aceship)")
else:
# 2回目:Fexli氏のリポジトリで再試行
fallback_url = fallback_base_url + dir + filename
response = requests.get(fallback_url)
if response.status_code == 200:
with open(save_path, "wb") as f:
f.write(response.content)
print(f"保存しました: {save_path}(from:Fexli)")
else:
print(f"ダウンロード失敗: {bg_url} および {fallback_url}")
# ファイル名を読み込み済みリストに追加
readList.append(filename)画像データはExcelファイルに情報が記録されており、2.4節で既にstoryPlotsResultに保存済みです。基本はExcelにURLが記載されたAceshipさんのgithubから画像をダウンロードしますが、一部対応していない画像についてはFexliさんのgithub(ASTR)からダウンロードしています。
さらに、字幕を読みやすくするために背景画像を全体的に暗くする処理を実施します。以下のコードで一括で暗くできます。
# 背景画像を少し暗くする(字幕が見えやすいように)
import cv2
for imgname in readList:
img_path = os.path.join("img", imgname)
image = cv2.imread(img_path)
adjusted_image = cv2.convertScaleAbs(image, alpha=0.6, beta=0)
cv2.imwrite("temp/" + imgname, adjusted_image)3.2.タイムラインデータを作成
動画編集ソフトに読み込むために、背景画像と音声ファイルの配置データを作成します。
以下のコードを実行することで、タイムランデータをautogenerated_timeline.xmlとしてoutputフォルダ内に保存できます。FinalCutPro7形式のXMLファイルとして一般的に使用できる形で出力しています。
# タイムライン出力
import os
from pydub import AudioSegment
output_dir = "output"
fps = 30
frame_multiplier = fps
wavMaeginFrame = (voiceMargin*fps // 1000) # 音声ファイル間に空白を設ける
video_clipitems = []
audio_clipitems = []
current_frame = 0
seen_images = set()
header = (
'<?xml version="1.0" encoding="UTF-8"?>\n'
'<!DOCTYPE xmeml>\n'
'<xmeml version="5">\n'
' <sequence>\n'
' <name>Timeline 1 (Resolve) (Resolve) (Resolve)</name>\n'
' <rate>\n'
' <timebase>30</timebase>\n'
' </rate>\n'
'<media>\n'
' <video>\n'
' <track>\n'
)
footer = (
' </track>\n'
' <format>\n'
' <samplecharacteristics>\n'
' <width>1920</width>\n'
' <height>1080</height>\n'
' <pixelaspectratio>square</pixelaspectratio>\n'
' </samplecharacteristics>\n'
' </format>\n'
' </video>\n'
' <audio>\n'
' <track>\n'
)
end = (
' </track>\n'
' </audio>\n'
'</media>\n'
'</sequence>\n'
'</xmeml>\n'
)
for idx, item in enumerate(storyplotsResult):
wav_path = os.path.abspath(os.path.join(output_dir, item["wavfile"]))
if not os.path.exists(wav_path):
print(f"警告: {wav_path} が存在しません。スキップします。")
continue
bg_path = os.path.abspath(os.path.join("temp", item["imgFile"]))
if not os.path.exists(bg_path):
print(f"警告: {bg_path} が存在しません。")
bg_path = os.path.join("img", "bg_black.png")
audio = AudioSegment.from_wav(wav_path)
duration_sec = audio.duration_seconds
duration_frames = int(duration_sec * frame_multiplier)
start = current_frame
endf = current_frame + duration_frames
out = duration_frames if duration_frames > 0 else 1
storyplotsResult[idx]["frameRange"] = [start, endf + wavMaeginFrame]
# Video clipitem
img_filename = os.path.basename(bg_path)
if img_filename not in seen_images:
video_clipitems.append(
f""" <clipitem>
<start>{start}</start>
<end>{endf + wavMaeginFrame}</end>
<in>0</in>
<out>{out + wavMaeginFrame}</out>
<file id="{img_filename} media">
<pathurl>file://{bg_path}</pathurl>
</file>
</clipitem>\n"""
)
seen_images.add(img_filename)
else:
video_clipitems.append(
f""" <clipitem>
<start>{start}</start>
<end>{endf + wavMaeginFrame}</end>
<in>0</in>
<out>{out + wavMaeginFrame}</out>
<file id="{img_filename} media"/>
</clipitem>\n"""
)
# Audio clipitem
wav_filename = os.path.basename(wav_path)
audio_clipitems.append(
f""" <clipitem>
<start>{start}</start>
<end>{endf}</end>
<in>0</in>
<out>{out}</out>
<file id="{wav_filename} media">
<pathurl>file://{wav_path}</pathurl>
</file>
<sourcetrack>
<mediatype>audio</mediatype>
<trackindex>1</trackindex>
</sourcetrack>
</clipitem>\n"""
)
current_frame = endf + wavMaeginFrame
xml_content = (
header +
"".join(video_clipitems) +
footer +
"".join(audio_clipitems) +
end
)
os.makedirs(output_dir, exist_ok=True)
output_path = os.path.join(output_dir, "autogenerated_timeline.xml")
with open(output_path, "w", encoding="utf-8") as f:
f.write(xml_content)
print(f"Final Cut Pro XMLを書き出しました: {output_path}")XMLファイルの詳細については以下の記事でも触れているので、よければ参照してください。

3.3.字幕データを作成
動画編集ソフトに読み込むために、字幕データを作成します。
以下のコードを実行することで、字幕データをautogenerated_subtitles.srtとしてoutputフォルダ内に保存できます。こちらも.srtファイルとして一般的に使用できる形で出力しています。
# 字幕出力
import os
from pydub import AudioSegment
output_dir = "output"
fps = 30 # フレームレート
srt_lines = []
current_frame = 0
subtitle_idx = 1
def sec_to_srt_time(sec):
hours = int(sec // 3600)
minutes = int((sec % 3600) // 60)
seconds = int(sec % 60)
milliseconds = int((sec - int(sec)) * 1000)
return f"{hours:02}:{minutes:02}:{seconds:02},{milliseconds:03}"
for idx, item in enumerate(storyplotsResult):
# item["frameRange"] = [500*idx, 500*idx+499] # 字幕表示テスト用
start_time, end_time = map(lambda f: f/fps, item["frameRange"])
start_str = sec_to_srt_time(start_time)
end_str = sec_to_srt_time(end_time)
srt_lines.append(f"{subtitle_idx}")
srt_lines.append(f"{start_str} --> {end_str}")
srt_lines.append(f"【{item['subtitle']}】")
# タグ装飾を施す
for plot in item["plots"]:
if plot["speaker"] == None:
subtitle_text = "\n".join(plot["text"])
elif plot["speaker"] == "":
subtitle_text = "\u3000" + "\n\u3000".join(plot["text"]) + ""
else:
subtitle_text = "<u>" + plot["speaker"] + "</u>\u3000" + "\n\u3000".join(plot["text"])
srt_lines.append(subtitle_text)
srt_lines.append("") # 空行
subtitle_idx += 1
srt_output_path = os.path.join(output_dir, "autogenerated_subtitles.srt")
with open(srt_output_path, "w", encoding="utf-8") as f:
f.write("\n".join(srt_lines))
print(f"SRT字幕ファイルを出力しました: {srt_output_path}")3.4.DavinciResolveで読み込む
タイムラインデータ・字幕データが作成できたので、これらを動画編集ソフトで読み込んでいきます。
Davinci Resolveの場合は、以下の手順で読み込めます
❶ 新規プロジェクトの作成(名前は適当につける)
❷上部のタスクバーから、ファイル>読み込み>タイムライン>autogenerated_timeline.xmlを選択>OK
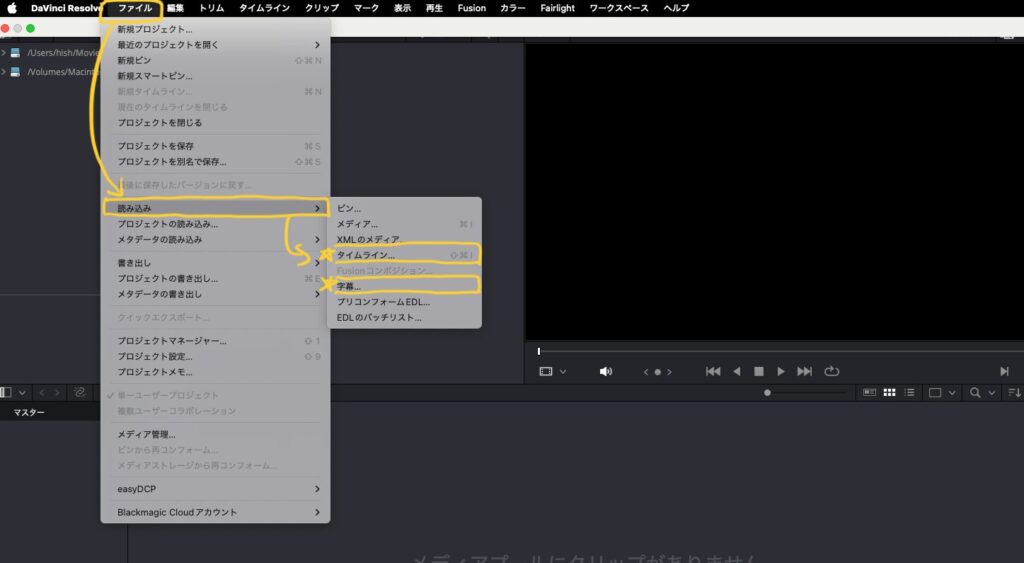
❸ 同じくタスクバーから、ファイル>読み込み>字幕>autogenerated_subtitles.srtを選択
❹ タイムラインに移動して、メディア欄のautogenerated_subtitlesをタイムラインにドラッグ&ドロップ
※字幕データの左端が0:00:00に合うように配置する
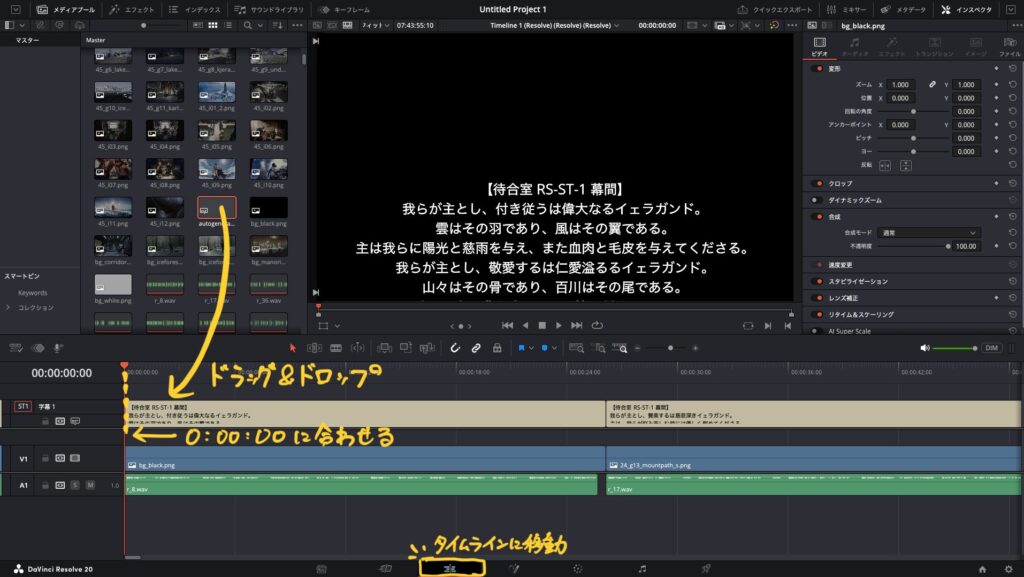
❺ 字幕の位置やサイズをいい感じに調整する
字幕を一つクリック>トラックから字幕の位置が調整できます。デフォルトから、左揃え・アンカーを上端・左端・位置とズームを程よく調整してください。
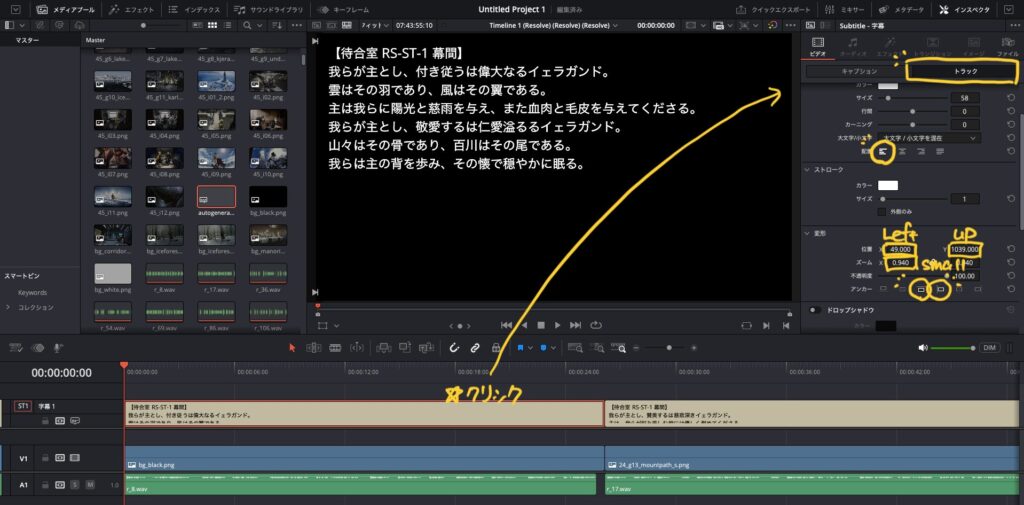
参考値として、位置X=49, Y=1039, ズーム=0.94程度でいい感じになります。
3.5.動画書き出し
タイムラインへの配置が完了したので、いよいよ動画として出力します。
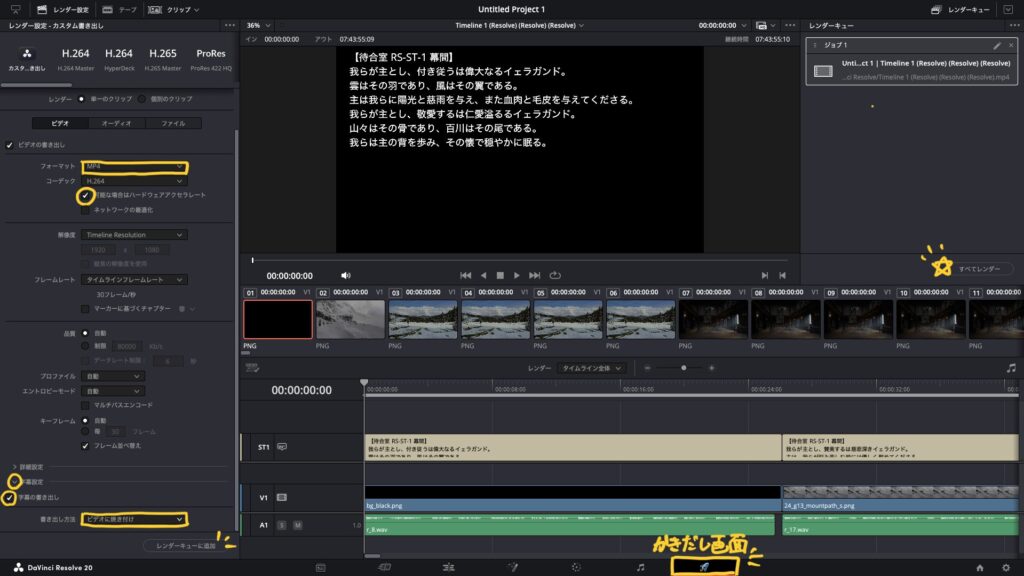
出力画面に移動して、以下の設定を変更します。
- フォーマット:mp4(お好みのフォーマットに)
- 可能な場合はハードウェアアクセラレートを選択(書き出しが早くなるかも)
- 字幕の書き出しをチェック→ビデオに焼き付けを選択
設定後、レンダーキューに追加をクリックして保存先フォルダを選択。全てレンダーをクリックすることで書き出しが始まります。私の環境では、書き出しに1時間ほどかかりました。
作成された動画は7時間44分、22.4GBの巨大動画ファイルになります。
3.6.あとは動画を楽しむだけ
あとは、この動画をPC内やドライブなどに保存して楽しむだけです。
とはいえ22GBもあっては扱いも難しく、気軽にスマホなどで楽しめるものでもないかもしれません…。YouTubeに非公開でアップロードするなども方法の一つですが、非公開でのアップロードが著作権法における「私的利用」に含まれるかは怪しく、あまり推奨はできません。
結局、2.6節で紹介した音声データとして楽しむ方法が無難かもしれません。
完成品の総評
完成した動画を聞いてみた感想ですが、かなり良いです。じっくり読まなくともながら聞きでストーリーを摂取できて、これなら無理なくストーリーを履修していけそうです。
VoiceVoxの読み上げに関しては、漢字の読み方や用語の読み方・アクセントは少し違和感がある部分も多い印象でした。とはいえ、無料の合成音声エンジンとしては十分すぎる性能なので、これ以上を求めるのであれば有料ツールを導入するのが無難かもしれません。
一点気になる点としては、読み上げの感情が少なく少し淡白な印象があります。今はさほど気にしていませんが、ストーリーの盛り上がりを感じにくくいずれ飽きがきてしまうこともあるかもしれません。
後書き
Python・VoiceVoxEngine・DavinciResolveを用いて、アークナイツのストーリーを字幕付き動画化する方法についてまとめました。皆さんの良きアークナイツライフの一助となれば幸いです。
途中で手順に詰まった場合は、とりあえずChatGPTに投げてみると大体解決するのでおすすめです。解決しないご質問があれば、気軽にX(Twitter)までお声がけください。
また、アークナイツの戦友も募集しています。
枠は大体空いているので、気軽に申請してください~